在全球大模型竞赛进入深水区的当下,Mistral Small4的发布标志着开源社区首次具备与商业巨头抗衡的全栈能力。该模型突破性地采用6B激活参数的MoE架构,在保持高性能的同时将端到端响应速度提升40%,其吞吐量更是前代产品的3倍,这种"高性能+低能耗"特性为边缘计算场景提供了新的想象空间。
硬件适配性成为本次升级的关键看点。根据官方技术白皮书,部署该模型至少需要4张NVIDIA H100加速卡,而理想运行环境需配置最新H200或B200芯片组。这一要求折射出当前AI产业面临的算力困境——模型性能的跃升始终与芯片进化保持强关联,预计将推动全球AI服务器市场进入新一轮升级周期。
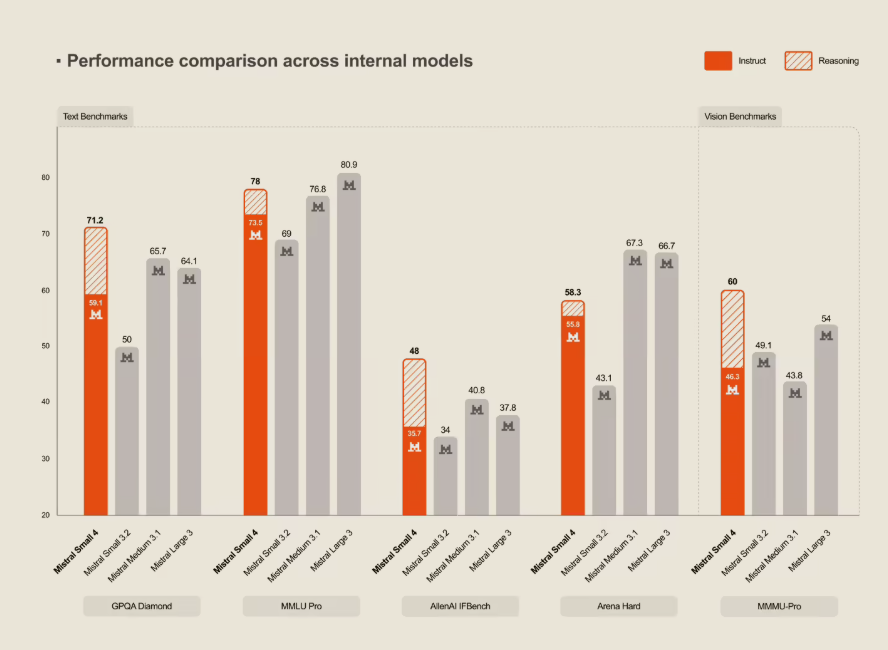
值得注意的是,Mistral Small4在三大基准测试中与GPT-OSS120B平分秋色的表现,打破了开源模型长期以来的性能天花板。其采用的Apache2.0协议不仅降低企业使用门槛,更可能引发连锁反应——包括云计算厂商在内的基础设施服务商或将调整其技术路线图。