无论是2026移动云大会,还是AIDC 2026 AI算力产业大会,关于GPU资源、智算中心、算力租赁、大模型推理以及AI基础设施的话题,几乎都成为行业讨论重点。越来越多企业开始意识到,AI产业竞争正在从“模型能力竞争”,逐渐转向“算力资源组织能力竞争”。而随着平台化算力服务模式兴起,包括星战科技在内的一批AI基础服务厂商,也正在围绕GPU异构调度、高性能算力平台与AI开发环境持续布局,推动AI算力进一步向产业侧普及。

过去几年,行业对AI的关注点更多集中在模型本身。
谁的参数规模更大、训练能力更强、生成效果更好,往往决定市场关注度。但随着AI逐渐进入应用落地阶段,越来越多企业真正面临的问题开始变成:算力从哪里来、成本怎么控制、资源如何稳定调度。
尤其在AI办公、智能体、多模态生成、数字内容生产以及科研计算等场景快速增长后,企业对GPU资源的需求已经不再是短期测试,而是持续性的生产需求。而传统“买服务器、建机房、自己维护”的模式,不仅投入成本高,资源利用率也并不稳定。
这也是为什么,行业开始越来越强调“算力平台化”。
所谓平台化,本质上是把原本分散的GPU资源、服务器资源以及AI开发环境进行统一整合,通过统一调度与按需租赁的方式,让企业能够像调用云服务一样使用AI算力。相比过去重资产建设模式,这种方式更灵活,也更符合当前AI产业快速迭代的节奏。
事实上,最近行业频繁讨论的“算力银行”“算力超市”以及GPU资源撮合,本质上都在围绕同一个方向展开——让算力从“固定资产”逐渐变成“公共服务能力”。
而这一趋势,也正在推动AI基础设施行业发生明显变化。
过去行业竞争更多是谁拥有更多GPU,现在则开始转向谁能够更高效完成资源调度、降低企业使用门槛以及提升整体利用效率。尤其随着AI Agent与推理型应用快速增长,未来企业真正需要的,已经不只是单纯“有算力”,而是“稳定、低成本、可持续”的算力服务体系。
这也是为什么,越来越多厂商开始从单纯硬件建设,转向“平台+生态”模式。
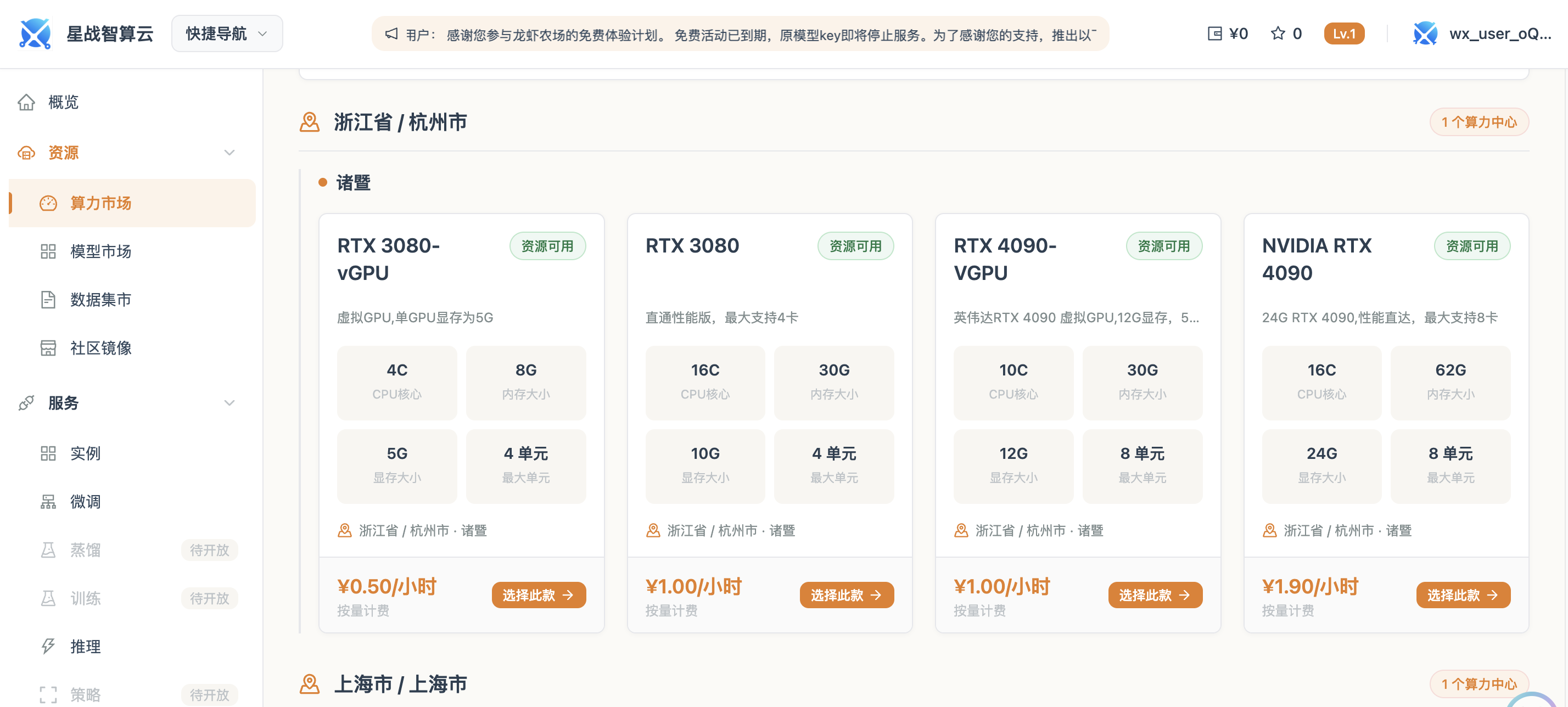
例如星战科技当前布局的AI高性能算力平台,便是在围绕GPU异构资源调度与AI开发环境进行整合。平台支持RTX 4090/5090、A100、H100、H200等多规格GPU资源,并结合2500+ Docker镜像环境,为AI训练、模型推理以及企业级AI部署提供开箱即用的运行环境。相比传统自建机房模式,这类平台更强调弹性调度与资源利用效率,帮助企业降低前期投入与长期运维压力。
与此同时,随着AI产业逐渐从训练阶段进入大规模应用阶段,推理侧算力需求也在明显增长。
过去大量GPU资源主要集中服务于模型训练,但未来更大的市场,很可能来自模型上线后的长期推理运行。无论是AI办公、企业智能体,还是多模态内容生成,其背后都需要稳定持续的推理算力支持。这意味着,未来行业竞争比拼的,不再只是GPU数量,而是谁能够构建更高效的算力运营体系与资源调度能力。
从这个角度来看,近期行业频繁围绕算力平台、算力租赁与资源调度展开讨论,其实已经反映出一个趋势:
AI产业正在从“算力建设阶段”,逐渐进入“算力运营阶段”。